


Omni Raise Series B $69m, Databricks +Palantir, ClickHouse Acquires HyperDX, DuckDB UI #75 w/e 14 Mar 2025
Join the 5,200-strong data herd getting all you need to know about Data for your Friday roundup


There are going to be some big big things over the coming weeks. Please share and subscribe if the below are of interest
Streaming Wars V2 - we released it! And what a read it is
https://www.getorchestra.io/blog/the-streaming-wars-2-0

Metadata Frameworks in Orchestra
Problem: there are often hundreds or thousands of tables that all need ingesting. The logic is common across them, and managing them is hard
Solution today: store a list of tables in a SQL database with metadata such as where the tables live, how they should be ingested, so on and so forth. Have an Azure Data Factory job that fetches this metadata, and spawns other Azure Data Factory Pipelines that in turn process data
Problem: This is unwieldy in ADF and causes “pipelines upon pipelines upon pipelines”. Table-level dependencies between Assets are also difficult to build.
Solution: use Orchestra’s Metadata Framework to define a set of Modular components that retain lineage at an Asset Level across all operations.
Sneak peek:

Things that make you go hmm
We don’t really care what other marketing teams do but as data engineers and programmers we value consistency. After all - there’s nothing worse than two conflicting definitions of the same thing.
This kind of self-righteous attitude:

isn’t really consistent with copying Orchestra’s .yml-based framework for building and managing data pipelines. Of course in reality, everyone in the industry knows having a declarative way to build pipelines is fastest, and really it’s not plagiarism at all because everyone who’s done this for more than 3 years knows it’s the fastest way.
Which begs the question - if everyone in the orchestration space has the same vision what’s the fundamental difference between any of us?
I for one believe it’s in our ability to deliver a value proposition that’s consistent over time (insofar as it can be). At Orchestra we are focussed on helping data engineers drive value by abstracting away the boring, tedious bits of connectivity you need for orchestration, observability, and monitoring. From day 0 to now, that’s never changed.
Nobody likes a flake!
Meme Drop
We don’t have any fire memes this week, but we do have this cool screenshot that shows how you can run a single task in Orchestra:
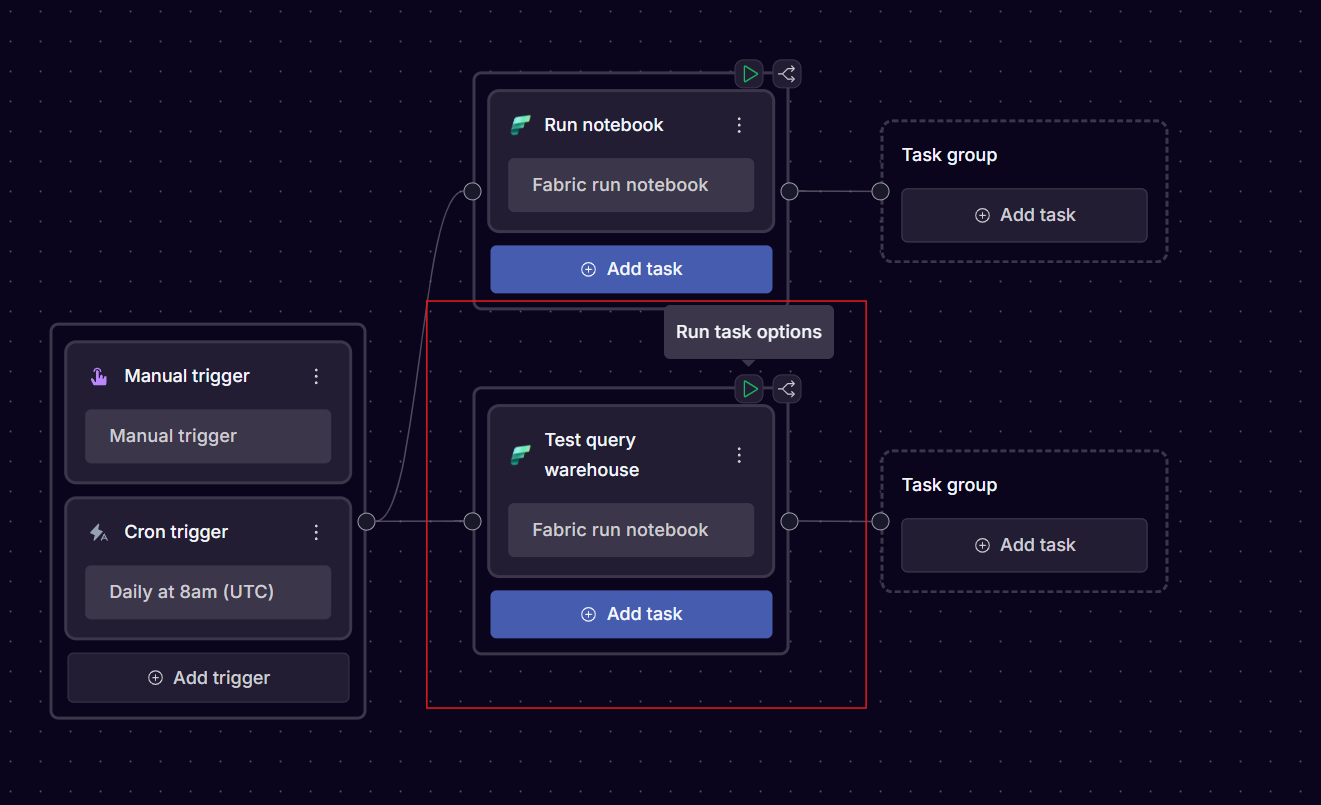
Very nice for debugging? You would be correct.
Medium 🧠
🧠 2026 Will Be The Year of Data + AI Observability (link)
🧠 Fourier Transform Applications in Literary Analysis (link)
🧠 🚀 How I built a Travel Agency Data Platform (link)
🧠 The Streaming Wars 2.0 (link)
🧠 Platform-Mesh, Hub and Spoke, and Centralised | 3 Types of data team (link)
🧠 Dynamic DML Generation Using Snowflake Cortex AI Functions: Turning PDF Scans Into Structured Data (link)
LinkedIn🕴
🕴 The Art of Writing: A Conversation with Simon Späti ✍️ (link)
🕴 Strengthening Data Quality: Snowflake & Anomalo Partnership (link)
🕴 Data Governance can be Cool (link)
🕴 AI, Data & Strategy at #Data4Breakfast 🔥 (link)
🕴 Harnessing Remote Functions: Extend BigQuery with External Processing (link)
🕴 ClickHouse Acquires HyperDX: Advancing Open-Source Observability! 🚀 (link)
🕴 Databricks & Palantir: AI-Powered Data Partnership (link)
News 📰
Editor’s Pick
📰 Omni raises $69M to design tools that help companies better analyze their data - Employees at many companies today are expected to make decisions through careful data analysis, but the tools they need to do it are clunky, slow or — in some cases — don’t exist. Read More
📰 NTT DATA Forges Strategic Partnership with Databricks to Advance Data and AI Platforms - TOKYO – March 10, 2025 – NTT DATA, a global digital business and IT services leader, signed a strategic partnership agreement with Databricks Inc. (hereinafter “Databricks”) on January 22, 2025 (January 21, 2025, U.S. time). Read More
📰 Bria lands new funding for AI models trained on licensed data - AI-powered image generators, which are at the center of a number of copyright lawsuits against AI companies, are frequently trained on massive amounts of data from public websites. Most of these companies argue that fair use doctrine shields their data-scraping and training practices. But many copyright holders disagree. Read More
YouTube and Podcast 🎥
Editor’s Pick
🎥 Connection woes using Power BI Direct Lake and an App??? (link)
🎥 DuckDB UI – Local Interface for DuckDB CLI (link)
Special 💫
💫 Cutter Associate’s 2025 trends for Data Platforms (link)
💫 The Cloud Judgement newsletter (link)
Jobs 💼
💼 PT Sr Python Eng at Source Medium (link)
💼 Senior Analytics Engineer at Paytient (link)
💼 Lead GTM Data Analyst at Life at Dashlane (link)
💼 Staff Engineer, Data & Analytics at Kinaxis (link)
💼 Data Product Owner at SonarSource (link)
Want to save on your ingestion bills? You’ll love this
You can leverage Python for lightweight ELT integrations. Here you’re only paying for compute and not being penalised by row-based pricing models. Pretty neat right? Check it out below / head to Orchestra and start today.
The best place to run dbt?
Don’t believe us? Watch the video below.